Jun 28, 2018
With more than 300 universities and companies represented, the Georgia Institute of Technology ranks #14 for the number of accepted papers at the International Conference on Machine Learning (ICML) in Stockholm, Sweden, July 10-15.
ICML is the leading international machine learning conference and is supported by the International Machine Learning Society (IMLS). This year marks the 35th year for the conference.
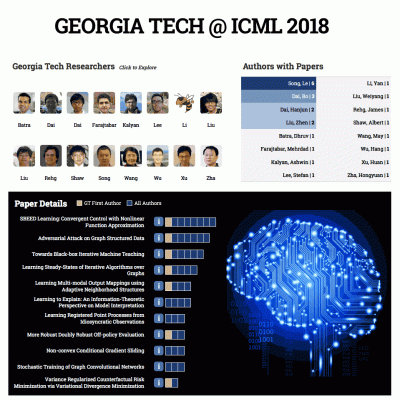
Throughout the five-day conference, more than seven Georgia Tech faculty members and eight students will present 11 papers through oral presentations, poster sessions, tutorials, invited talks, and workshops.
The group will have representatives from the School of Interactive Computing, the School of Computational Science and Engineering, the Machine Learning Center at Georgia Tech, and the GVU Center. Associate Director of Georgia Tech’s Machine Learning Center, Le Song, leads the pack contributing to six of the 11 papers.
“It's great to see that Georgia Tech continues to make great scientific contributions to the international machine learning community, especially in the area of deep learning over graphs and reinforcement learning,” said Song.
The conference takes place in conjunction with the International Joint Conference on Artificial Intelligence (IJCAI), the International Conference on Autonomous Agents and Multiagent Systems (AAMAS), and the International Conference on Case-Based Reasoning (ICCBR).
Below are the titles and abstracts from each of Georgia Tech’s papers. An interactive data graphic is available and allows users to explore the papers, authors, and presentation schedule. Coverage will be available during the conference on Twitter at @mlatgt and Instagram at @mlatgeorgiatech.
Georgia Tech at ICML 2018
Non-convex Conditional Gradient Sliding
chao qu (technion) · Yan Li (Georgia Institute of Technology) · Huan Xu (Georgia Tech)
Abstract: We investigate a projection free method, namely conditional gradient sliding on batched, stochastic and finite-sum non-convex problem. CGS is a smart combination of Nesterov's accelerated gradient method and Frank-Wolfe (FW) method, and outperforms FW in the convex setting by saving gradient computations. However, the study of CGS in the non-convex setting is limited. In this paper, we propose the non-convex conditional gradient sliding (NCGS) which surpasses the non-convex Frank-Wolfe method in batched, stochastic and finite-sum setting.
Learning to Explain: An Information-Theoretic Perspective on Model Interpretation
Jianbo Chen (University of California, Berkeley) · Le Song (Georgia Institute of Technology) · Martin Wainwright (University of California at Berkeley) · Michael Jordan (UC Berkeley)
Abstract: We introduce instance wise feature selection as a methodology for model interpretation. Our method is based on learning a function to extract a subset of features that are most informative for each given example. This feature selector is trained to maximize the mutual information between selected features and the response variable, where the conditional distribution of the response variable given the input is the model to be explained. We develop an efficient variational approximation to the mutual information, and show the effectiveness of our method on a variety of synthetic and real data sets using both quantitative metrics and human evaluation.
Learning Registered Point Processes from Idiosyncratic Observations
Hongteng Xu (InfiniaML, Inc) · Lawrence Carin (Duke) · Hongyuan Zha (Georgia Institute of Technology)
Abstract: A parametric point process model is developed, with modeling based on the assumption that sequential observations often share latent phenomena, while also possessing idiosyncratic effects. An alternating optimization method is proposed to learn a "registered" point process that accounts for shared structure, as well as "warping" functions that characterize idiosyncratic aspects of each observed sequence. Under reasonable constraints, in each iteration we update the sample-specific warping functions by solving a set of constrained nonlinear programming problems in parallel, and update the model by maximum likelihood estimation. The justifiability, complexity and robustness of the proposed method are investigated in detail, and the influence of sequence stitching on the learning results is examined empirically. Experiments on both synthetic and real-world data demonstrate that the method yields explainable point process models, achieving encouraging results compared to state-of-the-art methods.
Stochastic Training of Graph Convolutional Networks
Jianfei Chen (Tsinghua University) · Jun Zhu (Tsinghua University) · Le Song (Georgia Institute of Technology)
Abstract: Graph convolutional networks (GCNs) are powerful deep neural networks for graph-structured data. However, GCN computes the representation of a node recursively from its neighbors, making the receptive field size grow exponentially with the number of layers. Previous attempts on reducing the receptive field size by subsampling neighbors do not have a convergence guarantee, and their receptive field size per node is still in the order of hundreds. In this paper, we develop control variate-based algorithms, which allow sampling an arbitrarily small neighbor size. Furthermore, we prove new theoretical guarantee for our algorithms to converge to a local optimum of GCN. Empirical results show that our algorithms enjoy a similar convergence with the exact algorithm using only two neighbors per node. The runtime of our algorithms on a large Reddit dataset is only one seventh of previous neighbor sampling algorithms.
Variance Regularized Counterfactual Risk Minimization via Variational Divergence Minimization
Hang Wu (Georgia Institute of Technology) · May Wang (Georgia Institute of Technology)
Abstract: Off-policy learning, the task of evaluating and improving policies using historic data collected from a logging policy, is important because on-policy evaluation is usually expensive and has adverse impacts. One of the major challenges of off-policy learning is to derive counterfactual estimators that also have low variance and thus low generalization error.
In this work, inspired by learning bounds for importance sampling problems, we present a new counterfactual learning principle for off-policy learning with bandit feedbacks. Our method regularizes the generalization error by minimizing the distribution divergence between the logging policy and the new policy, and removes the need for iterating through all training samples to compute sample variance regularization in prior work. With neural network policies, our end-to-end training algorithms using variational divergence minimization showed significant improvement over conventional baseline algorithms and are also consistent with our theoretical results.
More Robust Doubly Robust Off-policy Evaluation
Mehrdad Farajtabar (Georgia Tech) · Yinlam Chow (DeepMind) · Mohammad Ghavamzadeh (Google DeepMind and INRIA)
Abstract: We study the problem of off-policy evaluation (OPE) in reinforcement learning (RL), where the goal is to estimate the performance of a policy from the data generated by another policy(ies). In particular, we focus on the doubly robust (DR) estimators that consist of an importance sampling (IS) component and a performance model, and utilize the low (or zero) bias of IS and low variance of the model at the same time. Although the accuracy of the model has a huge impact on the overall performance of DR, most of the work on using the DR estimators in OPE has been focused on improving the IS part, and not much on how to learn the model. In this paper, we propose alternative DR estimators, called more robust doubly robust (MRDR), that learn the model parameter by minimizing the variance of the DR estimator. We first present a formulation for learning the DR model in RL. We then derive formulas for the variance of the DR estimator in both contextual bandits and RL, such that their gradients with reference to the model parameters can be estimated from the samples, and propose methods to efficiently minimize the variance. We prove that the MRDR estimators are strongly consistent and asymptotically optimal. Finally, we evaluate MRDR in bandits and RL benchmark problems, and compare its performance with the existing methods.
Adversarial Attack on Graph Structured Data
Hajun Dai (Georgia Tech) · Hui Li (Ant Financial Services Group) · Tian Tian () · Xin Huang (Ant Financial) · Lin Wang () · Jun Zhu (Tsinghua University) · Le Song (Georgia Institute of Technology)
Abstract: Deep learning on graph structures has shown exciting results in various applications. However, little attention has been paid to the robustness of such models, in contrast to numerous research works for image or text adversarial attack and defense. In this paper, we focus on the adversarial attacks that fool the model by modifying the combinatorial structure of data. We first propose a reinforcement learning based attack method that learns the generalizable attack policy, while only requiring prediction labels from the target classifier. Also, variants of genetic algorithms and gradient methods are presented in the scenario where prediction confidence or gradients are available. We use both synthetic and real-world data to show that, a family of Graph Neural Network models is vulnerable to these attacks, in both graph-level and node-level classification tasks. We also show such attacks can be used to diagnose the learned classifiers.
Learn from Your Neighbor: Learning Multi-modal Mappings from Sparse Annotations
Ashwin Kalyan (Georgia Tech) · Stefan Lee (Georgia Institute of Technology) · Anitha Kannan (Curai) · Dhruv Batra (Georgia Institute of Technology / Facebook AI Research)
Abstract: Many structured prediction problems (particularly in vision and language domains) are ambiguous, with multiple outputs being ‘correct’ for an input – e.g. there are many ways of describing an image, multiple ways of translating a sentence; however, exhaustively annotating the applicability of all possible outputs is intractable due to exponentially large output spaces (e.g. all English sentences). In practice, these problems are cast as multi-class prediction, with the likelihood of only a sparse set of annotations being maximized – unfortunately penalizing for placing beliefs on plausible but unannotated outputs. We make and test the following hypothesis – for a given input, the annotations of its neighbors may serve as an additional supervisory signal. Specifically, we propose an objective that transfers supervision from neighboring examples. We first study the properties of our developed method in a controlled toy setup before reporting results on multi-label classification and two image-grounded sequence modeling tasks – captioning and question generation. We evaluate using standard task-specific metrics and measures of output diversity, finding consistent improvements over standard maximum likelihood training and other baselines.
Towards Black-box Iterative Machine Teaching
Weiyang Liu (Georgia Tech) · Bo Dai (Georgia Institute of Technology) · Xingguo Li (University of Minnesota) · Zhen Liu (Georgia Tech) · James Rehg (Georgia Tech) · Le Song (Georgia Institute of Technology)
Abstract: In this paper, we make an important step towards the black-box machine teaching by considering the cross-space machine teaching, where the teacher and the learner use different feature representations and the teacher can not fully observe the learner's model. In such scenario, we study how the teacher is still able to teach the learner to achieve faster convergence rate than the traditional passive learning. We propose an active teacher model that can actively query the learner (i.e., make the learner take exams) for estimating the learner's status and provably guide the learner to achieve faster convergence. The sample complexities for both teaching and query are provided. In the experiments, we compare the proposed active teacher with the omniscient teacher and verify the effectiveness of the active teacher model.
Learning Steady-States of Iterative Algorithms over Graphs
Hajun Dai (Georgia Tech) · Zornitsa Kozareva () · Bo Dai (Georgia Institute of Technology) · Alex Smola (Amazon) · Le Song (Georgia Institute of Technology)
Abstract: The design of good heuristics or approximation algorithms for NP-hard combinatorial optimization problems often requires significant specialized knowledge and trial-and-error. Can we automate this challenging, tedious process, and learn the algorithms instead? In many real-world applications, it is typically the case that the same optimization problem is solved again and again on a regular basis, maintaining the same problem structure but differing in the data. This provides an opportunity for learning heuristic algorithms that exploit the structure of such recurring problems. In this paper, we propose a unique combination of reinforcement learning and graph embedding to address this challenge. The learned greedy policy behaves like a meta-algorithm that incrementally constructs a solution, and the action is determined by the output of a graph-embedding network capturing the current state of the solution. We show that our framework can be applied to a diverse range of optimization problems over graphs, and learns effective algorithms for the Minimum Vertex Cover, Maximum Cut and Traveling Salesman problems.
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
Bo Dai (Georgia Institute of Technology) · Albert Shaw (Georgia Tech) · Lihong Li (Microsoft Research) · Lin Xiao (Microsoft Research) · Niao He (UIUC) · Zhen Liu (Georgia Tech) · Jianshu Chen (Microsoft Research) · Le Song (Georgia Institute of Technology)
Abstract: When function approximation is used, solving the Bellman optimality equation with stability guarantees has remained a major open problem in reinforcement learning for decades. The fundamental difficulty is that the Bellman operator may become an expansion in general, resulting in oscillating and even divergent behavior of popular algorithms like Q-learning. In this paper, we revisit the Bellman equation, and reformulate it into a novel primal-dual optimization problem using Nesterov's smoothing technique and the Legendre-Fenchel transformation. We then develop a new algorithm, called Smoothed Bellman Error Embedding, to solve this optimization problem where any differentiable function class may be used. We provide what we believe to be the first convergence guarantee for general nonlinear function approximation, and analyze the algorithm's sample complexity. Empirically, our algorithm compares favorably to state-of-the-art baselines in several benchmark control problems.
Related Media
-
ICML 2018
-
Explore GT@ICML 2018