Oct 21, 2024
Improving Safety for Learning Enabled Systems
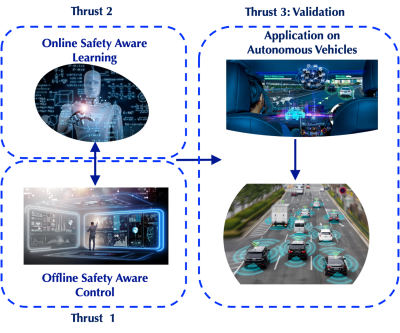
Vamvoudakis received $400,000 from the National Science Foundation for his proposal, “Improving Safety by Synthesizing Interacting Model-based and Model-free Learning Approaches.” This is the first grant on Safe Learning-enabled Systems (SLES) awarded to Georgia Tech from NSF. He and his team will establish a framework that leads to the design and implementation of SLES in which safety is ensured with high confidence levels. The framework will leverage tools from control theory, multi-agent autonomy, and formal methods for rigorously probabilistic reasoning to create safe learning-enabled systems. Before anyone releases an autonomous machine, the public expects it to be safe for those around it. For example, sensors in drones and other machines are sensitive to infiltration, malfunction, and the environment. If the wind is strong, the drone would need to be able to adjust to the environment, stay on course, and perhaps change altitude. If the drone encounters a telephone pole or even a person in its path, it would be able to adjust accordingly without waiting for human control.
His research approach will take elements from various theories and combine them to improve the safety of these LES within the machine.
“Our approach algorithmically combines model-based and model-free reinforcement learning for enhancing safety by using the learned model to predict how well a safe policy will behave and then update the resulting actions,” Vamvoudakis explained. “As a result, our approach does not rely on improving the model and does not require an infinite amount of time for convergence. Instead, our plan optimally enhances safety and combines the predefined time-convergent actions generated to achieve high performance in the specified task.”
The fundamental knowledge created in his research could inform how future-assured autonomous systems with embodied intelligence can be built. Their results could inform the design of key enablers of the global economy, including smart and connected cities, networked actions of smart and autonomous systems by enabling system flexibility, efficiency, and capacity, and automated financial trading, such as creating automated news digests around finance.
Gaming Strategies Inform Military LES Frameworks
Autonomous machines are changing the way that the military operates. Uncrewed battles between autonomous systems require the systems to learn and adapt to unknown environments and to distinguish allies from enemies. Learning-enabled systems are trained to take the circumstances at hand and give recommendations for the desired response.
When humans have control over these machines, this is considered humans in the loop. When humans move further into the background and give the machines decision-making autonomy, it is called humans on the loop. Humans would still have oversight, but the machine could ultimately decide without human approval.
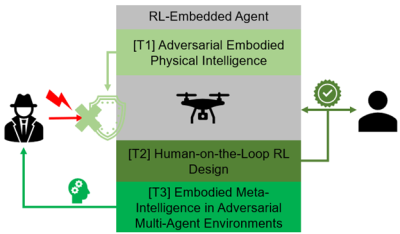
Through his newly awarded $480,000 project “Embodied and Secure Physical Intelligence with Possible Humans-on-the Loop in Complex Adaptive Systems” with the Army Research Office (ARO), Vamvoudakis and his team are developing decision-making algorithms to assist during conflict in adversarial environments. This is needed because military maneuvers can be unpredictable, and autonomous machines need to be able to adapt accordingly. He will use game-theoretic strategies to inform his work.
Vamvoudakis’ team has created algorithms in the context of games, where a “defender” wants to regulate a cyber-physical system around a trimming point, but an “attacker” intends to disrupt this regulation as much as possible.
They also employed level-k thinking to capture the behavior of the attacker. Particularly, instead of assuming that the attacker can reason perfectly about the behavior of the defender, the employed level-k thinking model imposed that the attacker can only make finitely-many (though arbitrarily many) steps of reasoning about what the defender might do, how the attacker can best respond to that, how the defender can then best respond.
The project is a continuation of his ARO YIP award that developed a way to understand different types of attackers in a unified framework. Attackers who think a little ahead are called low-level, while those who think more strategically, like those near a Nash equilibrium, are called high-level. This understanding helps create better defense strategies without assuming that attackers always act perfectly.
To demonstrate how this model works in real military situations, he and his students looked at it through the lens of a pursuit-evasion game. They found that using level-k thinking to understand and respond to attackers is more effective than assuming attackers always optimize their strategies perfectly.
MathWorks Gift to Enhance Learning for Artificial Intelligence
Current methods for protecting closed-loop reinforcement learning systems (artificial intelligence where the system continuously learns and adapts based on feedback from the environment) don't work well against potential threats. These existing methods often rely on guesswork, need a deep understanding of the system, and require a lot of training time. They also fail to guarantee safety when facing adversaries.
Vamvoudakis’ MathWorks gift, “Adversarial Reinforcement Learning” aims to create a new generation of smart, flexible, autonomous systems that can learn and adapt. This is the first-ever gift from MathWorks made to Georgia Tech.
“We will develop the next generation of agile, highly adaptive autonomous systems that use mechanisms from cognition and learning to process information from distributed sensors. In particular, looking to autonomous systems appearing in nature for inspiration,” he said. Specifically, behavioral scientists have validated the need for intermittent data sharing in learning tasks. They have shown that the central nervous system in human beings minimizes effort and sorts through impulses and stimuli by maintaining intermittent signaling. Specifically, the spinal cord transmits a channel of information and effectively exploits its neural resources via intermittent strategies to produce a sequence of muscle-bone interactions that induce movement.”
By looking to such ideas, they will develop safe and strong reinforcement learning methods to handle teamwork, assign tasks, and manage resources effectively. They will also collaborate with MathWorks to create useful toolboxes and provide internship opportunities.
Related Media
-
KV headshot Picture1.jpg
-
Picture2.png
-
Picture3.png